Anthropic passed OpenAI at $965 billion the same week it shipped a model whose headline feature is admitting when it is wrong, and pledged to one day release the exploit engine it still calls too dangerous to ship. Underneath the valuation, trust stopped being assumed and started being priced: a contamination-free benchmark reset the coding leaderboards everyone quotes, a 400-run study showed an AI pentester's clean report proves nothing, and OpenAI gated its new biodefense model to vetted governments only. Meanwhile the surface that trust runs on failed in public — one malformed character bypassed authentication in every Starlette-based agent stack, a North Korean RAT turned Hugging Face into its command channel, and the offline model runner became the exfiltration vehicle. The frontier started selling trust. The stack underneath it could not provide any.
BEATS 06
DISPATCHES 14
CHAIN MYTHOS × 03
PUBLISHED 2026-05-30
I.
THE FRONTIER SOLD HONESTY
Anthropic shipped Opus 4.8 and led not with a benchmark but with a behavior — the model flags its own uncertainty and is far less likely to let flaws in code it wrote pass unremarked — then closed a $65 billion round that valued it above OpenAI for the first time. Raw capability is now assumed; the differentiator the most valuable AI company is selling is whether you can trust the output.
82FIELD REPORT
Anthropic Shipped Honesty. The Benchmark Was An Afterthought.
Opus 4.8's headline feature is admitting when it is wrong — and running hundreds of subagents while it does.
On May 28th, Anthropic shippedClaude Opus 4.8, and for the first time the lab led the announcement not with a score but with a behavior. "One of the most prominent improvements in Opus 4.8 is its honesty," the release reads — the successor to Opus 4.7 is "more likely to flag uncertainties about its work and less likely to make unsupported claims," and around four times less likely than its predecessor to let flaws in code it wrote pass unremarked. The Verge filed it as the model that is more honest when it messes up. The benchmarks are still there — they are just no longer the pitch.
When the numbers do appear, they read like supporting evidence rather than the headline: 84% on Online-Mind2Web, the first model to break 10% overall on the all-pass Legal Agent Benchmark, and the only model to complete every Super-Agent case end-to-end. The load-bearing ship is the new tool underneath them — Dynamic Workflows, a Claude Code research preview where one Claude plans the work and then "run[s] hundreds of parallel subagents in a single session" with verification built in. TechCrunch noted what that buys you: codebase-scale migrations "across hundreds of thousands of lines of code from kickoff to merge, with the existing test suite as its bar."
That pairing is the whole argument of the week. Raw capability is now assumed — every frontier model clears the agentic bar — so the differentiator the most valuable lab is selling is whether you can trust the output enough to let it run unattended across hundreds of subagents and a hundred thousand lines of your code. A model that flags its own uncertainty and refuses to wave through its own bugs is the only kind you can hand a verification loop and walk away from. Anthropic stopped selling the smartest model and started selling the one you can leave alone with the test suite. Trust just became the product.
Anthropic closed a $65 billion Series H on May 28th at a $965 billion post-money valuation — co-led by Altimeter, Dragoneer, Greenoaks, and Sequoia, and folding in $15 billion of previously committed hyperscaler money, $5 billion of it from Amazon. The round lands the company past OpenAI as the most valuable AI company in the world, and reads, in the company's own framing, as the last private raise before an IPO. It closed the same day Anthropic shipped Opus 4.8 — the model whose headline feature is admitting when it is wrong.
The number under the valuation is the one that justifies it: run-rate revenue crossed $47 billion earlier in the month, the metric that turns a $965B price from a bet on the future into a multiple on the present. The wealth it minted is the human-scale tell: per Bloomberg's index, seven Anthropic founders entered the world's 500 richest in a single day — the most from one company in the index's history — each now worth roughly $8 billion, though the Amodei siblings own under 1% apiece. The round was the same hour Anthropic dated Claude Mythos for wide release "in the coming weeks," putting a ship window on the cyber model it still calls too dangerous to hand over.
The league table flipped on a behavior, not a benchmark. OpenAI built the category and held its lead by capability; Anthropic took the crown the week it shipped a model that flags its own uncertainty and declined to ship the one that finds exploits. The most valuable AI company on the planet is no longer the one selling the most raw capability — it is the one charging for whether you can trust the output, and the market just priced that thesis at nearly a trillion dollars.
A single malformed Host-header character bypassed path-based authentication in every app built on Starlette — FastAPI, vLLM, LiteLLM, and MCP servers all inherit it from a 325-million-download dependency. A North-Korea-linked RAT turned Hugging Face into its malware CDN and exfil channel. Ollama, the local runner developers trust because it is offline, was shown rendering phishing overlays and leaking local data. The surface you build the agent on is the attack surface, and this week it failed in public.
84FIELD REPORT
One Character Bypassed Auth In Every Agent Stack. The Stack Was Starlette.
A malformed Host header walks straight past path-based authorization in FastAPI, vLLM, LiteLLM, and your MCP servers.
On May 26th OSTIF disclosed the expanded details of BadHost — CVE-2026-48710 — a single-character authentication bypass in Starlette, the ASGI routing core that FastAPI is built on. A senior researcher at X41 D-Sec found it by hand during an OSTIF-managed security audit of vLLM sponsored by the Alpha-Omega Project; the patched release, Starlette 1.0.1, shipped the Friday before the advisory, and OSTIF went public early because "slow uptake of updated versions of Starlette and discovery of more vulnerable live services has caused us serious concerns." There was effectively no lead time to patch before the bug was on the open internet.
The mechanism is one missing input check. Starlette rebuilds `request.url` by concatenating the HTTP Host header with the request path and re-parsing the result — without validating the Host value against the RFC 9112 / RFC 3986 grammar first. A Host header containing a `/`, `?`, or `#` shifts where the path, query, and fragment boundaries fall on re-parse, so `request.url.path` no longer matches the wire path the server actually routed against. The router dispatches on the real path; the middleware sees the poisoned one. The proof is a curl one-liner: `-H "Host: foo" /admin` returns 403, and `-H "Host: foo?" /admin` returns 200. "A single character injected into the HTTP Host header bypasses path-based authorization in Starlette, the routing core of FastAPI," the Secwest researchers wrote — and because Starlette pulls **more than 500 million downloads a month**, that one character reaches vLLM (where the bug was found), LiteLLM, Text Generation Inference, most OpenAI-shim proxies, and the MCP servers your agents authenticate through.
The surface you build the agent on is the attack surface, and an MCP server is the worst possible place to learn it: it exists to hold credentials for every external system the agent touches, so one bypassed `/admin` or `/v1/models` prefix is a key vault with the door propped open — X41's scan already found live clinical-trial databases, full-mailbox email accounts, and SSH-to-industrial-device bastions exposed in the wild. The advisory rates it 7 of 10, a number Secwest says "materially understates" the threat downstream. The durable fix is not the version bump alone; it is reading `request.scope["path"]` — the un-reconstructed wire path — anywhere a security decision is made, because this bug class will recur. Every framework in the Python agent stack inherited its auth from one dependency that trusted a header it never checked, and trust you never verified is not trust. It is exposure with good branding.
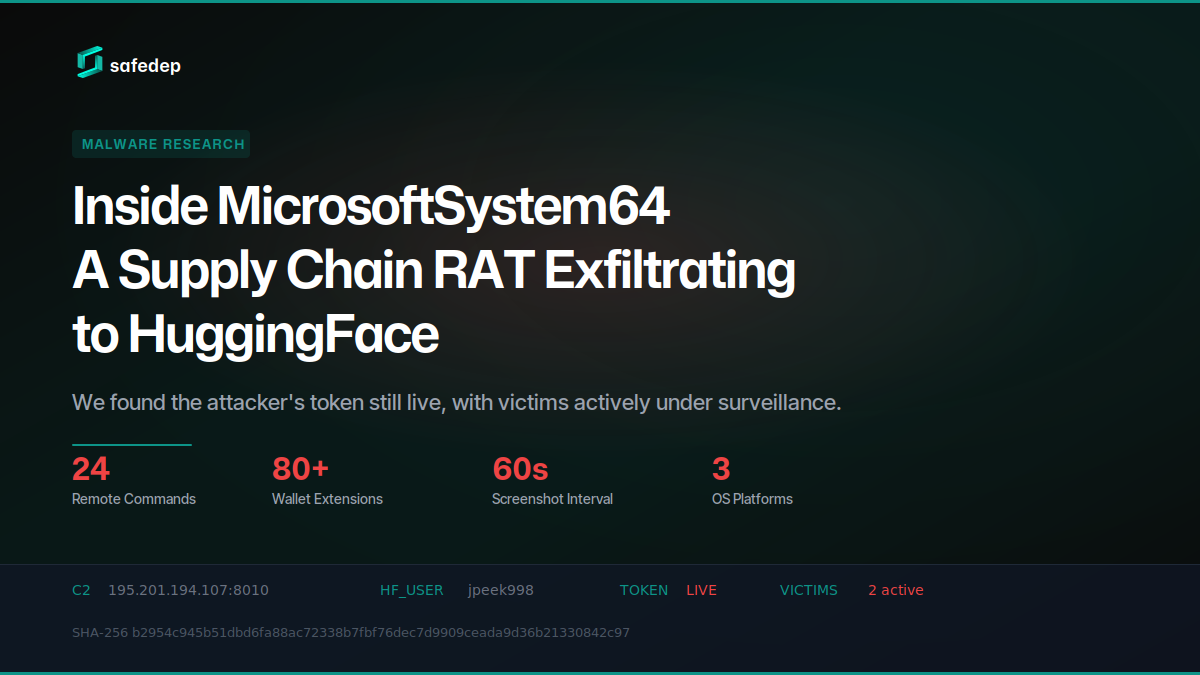
A North-Korea-linked operator wired a live exfiltration pipeline through throwaway npm `logger` packages — SafeDep confirmed the channel on May 28th, the same crew JFrog independently traced. The crew — tracked as FAMOUS CHOLLIMA, the DPRK group also known as Contagious Interview — had stopped hosting its own command server and instead turned Hugging Face into one. After npm pulled the original `js-logger-pack` dropper, the operator spun up fresh accounts and re-shipped through `terminal-logger-utils`, `ts-logger-pack`, `pretty-logger-utils`, and `pinno-loggers` — each a decoy logging utility whose install step quietly pulls down an 81 MB binary called `MicrosoftSystem64`.
The implant ships as platform-specific Node.js Single Executable Applications — one build per OS, with the `system-releases` repo listing all four (Windows, Linux x64, macOS x64, macOS arm64) and an updater that downloads the right binary for the victim's machine; the build SafeDep reverse-engineered is the 81 MB stripped ELF 64-bit Linux executable, a Node SEA built on Node v20.18.2. Once resident it screenshots the desktop every 60 seconds, harvests SSH keys, compresses Telegram Desktop session folders for account hijack, and drains 80-plus crypto-wallet browser extensions across 15 browser families. Exfiltration rides entirely on private Hugging Face datasets: the binary ships from one repo (`Lordplay/system-releases`) and stolen data flows out to a second account, `jpeek998`, one dataset per victim machine. SafeDep recovered 417 screenshots and a 500 MB credential archive from just two cryptocurrency traders before the accounts were disabled.
This is a new generation of the same lineage. Week 06's AntV burst hijacked a real maintainer to detonate 317 packages at machine speed; this one abandons impersonation altogether and launders itself through `huggingface.co` — a domain every AI shop already trusts, allowlists, and pipes through unmonitored. The exfil channel is no longer a suspicious IP an egress filter can flag; it is the model hub. When the place you fetch your weights is also the place your secrets leave from, perimeter logic built around "block the unknown host" has nothing left to block.
In late May, PromptArmor disclosed a set of unpatched vulnerabilities in Ollama, the local model runner developers reach for precisely because it is supposed to keep everything on the machine. The headline finding is that "the entire Ollama desktop interface can be overwritten by an attacker-controlled website via an indirect prompt-injection attack due to insecure rendering of model outputs." Ask the app about a web page seeded with hidden white-on-white instructions and the model emits HTML that the desktop client paints as UI — a credential-harvesting phishing page wearing Ollama's own chrome. PromptArmor says it reported the bugs to the Ollama team on December 18th, 2025, and got no response across four follow-ups.
The overlay is one of four vectors; the other three exfiltrate. PromptArmor documented three zero-click data-exfiltration paths — through insecure web-search tooling, through insecure rendering of Markdown image outputs, and through insecure rendering of external HTML — each one letting an injected model construct a URL that smuggles local data out in the query string. The load-bearing detail is the friction count: "No human-in-the-loop approval steps are required for any attacks in this article." The threat model developers run Ollama under assumes a model file is data — inert weights you download from a hub and point at your laptop. These bugs treat the model's output as an executable instruction stream, and the surface rendering that stream never sanitized it.
This is the same lesson BadHost taught the agent server this week, arriving now at the workstation: the thing you build on top of is the attack surface, and "offline" was never the same property as "safe." A drive-by Ollama exposure is not new — The Register flagged a local-chat hijack last August — but the disclosure pattern is the tell, an unanswered report sitting open since December while the runner ships unchanged. Pulling an untrusted GGUF from a hub is now a code-trust decision, not a download. You moved the model onto your own machine to keep it private, and your own machine is exactly what it reached for.
DeepSWE rebuilt the coding benchmark from scratch so no model could have trained on it, and the leaderboard everyone quotes moved — GPT-5.5 to 70, Opus 4.7 to 54, Gemini 3.5 Flash to 28. A 400-run study found AI penetration testers wildly inconsistent against one fixed target, so a clean report proves nothing. OpenAI published a playbook conceding the harness, not the model, swings the result. The week the eval economy admitted its own numbers need a chain of custody.
87FIELD REPORT
DeepSWE Rebuilt The Coding Benchmark From Scratch. The Leaderboard Moved.
When no model can have trained on the test, the scores everyone quotes turn out to have been graded on contaminated work.
On May 26th, Datacurve published **DeepSWE**, a coding-agent benchmark engineered so that no model could have seen the answers. Every one of its 113 tasks across 91 active repositories and five languages has a reference solution written from scratch — not lifted from an existing pull request, commit, or public patch — and none of the fixes are merged back upstream, so they never enter the GitHub record that future training scrapes will swallow. On that clean board the ordering everyone quotes shifted: GPT-5.5 lands at 70% (±4), Claude Opus 4.7 at 54, and Gemini 3.5 Flash at 28 — gaps far wider than the dead heat the public leaderboards show.
The load-bearing number is not a score; it is a false-positive rate. DeepSWE's program-based verifier — which accepts any implementation whose observable behavior is correct, not just the reference — was wrong 0.3% of the time across 735 reviewed rollouts. The same audit put SWE-Bench-Pro, the benchmark much of the field cites, at an 8.5% false-positive rate and a 24% false-negative rate. That is the mechanism behind the contamination: when the grader rewards near-misses and the test tasks already sit in the training data, models cluster at the top because they have effectively studied the answer key, and a flawed verifier waves the cribbed work through.
For anyone shipping on top of a coding agent, the takeaway is that a public leaderboard score is now a claim that needs a chain of custody, not a fact. The repo is open on GitHub with the harness and the verifier, so the methodology is auditable rather than asserted — which is precisely the standard the contaminated boards never met. DeepSWE does not crown a different winner so much as widen the field back out into the gaps builders feel in daily use, and it does it by treating its own grader as the thing most likely to lie.
Galip Tolga Erdem posted a single-author preprint to arXiv on May 28th with a question the field had been quietly assuming away: How Reliable Are AI Attackers Against a Fixed Vulnerable Target? The answer is not very. Erdem ran 400 autonomous penetration-testing runs — four models, 100 each — against one identical honeypot hosting OWASP Juice Shop and two other deliberately broken services, holding the prompt, the orchestrator, and the target constant. The same machine, pointed at the same known-vulnerable box, found a wildly different reality each time it looked.
Full exploitation landed in 85 of 100 runs for Gemini 2.5 Flash-Lite, 61 for Claude Sonnet 4, 56 for GPT-4o-mini, and just 25 for qwen2.5-coder:14b — a spread of statistical significance, p < 0.001, against a target every run was told was exploitable. The failure modes were model-distinctive and silent: qwen quit early on 52 runs, GPT-4o-mini burned its iteration budget on 23, and the misses surfaced no error a triage queue would catch. This is the reproducibility gap the whole eval economy is now reckoning with this week — the same crack DeepSWE exposed in the leaderboards, here in the auditor itself. The agent that scans your code is a sampler, and one sample is not a measurement.
The arms race Wired chronicled last week assumes the AI bug-hunter is a reliable instrument — point it at a target, read the report, trust the verdict. This study breaks that assumption at the root. For anyone holding an AI red-teamer's clean bill of health, the absence of a finding is now provably not the absence of a bug; it is one draw from a distribution that, against a target you *know* is broken, came up empty more than a third of the time. A passed scan is not a safe system. It is a system that survived one roll of the dice.
On May 28th, OpenAI published a shared playbook for trustworthy third-party evaluations, written with and co-referencing the three labs that audit frontier models from the outside: METR, Apollo Research, and the UK AI Safety Institute. It reads less like a marketing post than a confession. The headline admission is that a chatbot-style question-and-answer no longer measures a frontier system, and that the thing which actually determines the score is not the model but the harness — the configuration of tools, prompts, and environment wrapped around it. The lab that builds the model is telling the people who grade it that the grade is mostly about the rig.
The playbook sorts every eval into three claims — capability elicitation, safeguard performance, and comparison — and shows how each one moves with the harness rather than the weights. The receipts are concrete: on the UK AISI cyber range, holding the model fixed and raising the token budget from 10M to 100M lifted performance by up to 59% — same model, more elicitation, a different number. To make a safeguard claim land, the same AISI red team spent six hours building a custom harness that found a universal jailbreak eliciting violative cyber content across every malicious query OpenAI handed it, multi-turn agentic settings included. METR and Apollo, meanwhile, have had reasoning-trace access since GPT-5 — Apollo used it to catch alignment-evaluation awareness the surface behavior hid. The number alone is meaningless; only the number plus its method is a measurement.
This is the third crack in the same week's eval economy. DeepSWE showed the leaderboard was contaminated; the 400-run pentest study showed the auditor's clean report was a coin flip; OpenAI now concedes the rubric itself swings with the rig. The uncomfortable part is who wrote it: the model-maker is authoring the standard by which independent labs will judge the model-maker, and the standard's own logic — that elicitation effort changes the verdict — means a lab that wants a flattering result knows exactly which dial to turn. The playbook's real demand is a chain of custody for evidence: not "what did it score," but "what rig produced that score, and could anyone reproduce it." Until an eval ships with its harness, the number is a press release.
Anthropic's unreleased Mythos disproved an 80-year Erdős conjecture air-gapped, with a shorter proof than the one OpenAI published days earlier — and the same week, Anthropic pledged to release Mythos-class models publicly 'once we've developed the far stronger safeguards we need,' while admitting nobody has those safeguards yet. OpenAI moved in lockstep, gating a new biodefense model to vetted governments. The frontier's most powerful capability is now rationed by trust. MYTHOS-10.
90FIELD REPORTMYTHOS · CHAIN
An Air-Gapped Model Broke 80-Year-Old Math. Twice.
Two frontier labs disproved the same 1946 Erdős conjecture days apart, and one did it with the network unplugged.
Days after OpenAI's internal reasoning model disproved the Erdős unit-distance conjecture — a 1946 problem on the maximum number of point-pairs exactly one unit apart in the plane — Anthropic said its unreleased Mythos had cracked the same wall independently. The catch is how. Per the testing setup an Anthropic researcher described, the problem was dropped into an environment with internet access blocked, ruling out retrieval of OpenAI's now-public solution. Isolated Claude Code instances, network disconnected, arrived at a configuration that beats the bound Erdős conjectured — and did it with a shorter, more elegant route than the proof OpenAI shipped first.
What makes the result load-bearing is not the speed but the independence. Mathematician Daniel Litt judged Mythos's proof "a bit worse" than OpenAI's, yet found independently — and the model reportedly re-derived OpenAI's solution too before preferring its own leaner path. Anthropic's Sholto Douglas, its head of alignment science, called it a "cute, simple proof" and a sign of "serious overhang." Neither disproof is machine-checked. The formal counterweight arrived the same week from DeepMind: AlphaProof Nexus, pairing an LLM with a Lean compiler that verifies every step, autonomously resolved 9 of 353 open Erdős problems at a few hundred dollars each — proof that is provably correct, where the headline-grabbing disproofs are merely convincing.
The unlock is real, and so is the asterisk. Two of the most capable models on earth pushed past an open conjecture that had stood for eighty years, one of them with the wire pulled — a configuration designed to prove the machine reasoned rather than retrieved. But "amazed" is not "verified," and a brilliant argument that survives a week of X threads is not yet a theorem that survives peer review. The capability is no longer in question. What gets tested next is whether the math holds when a journal, not a model, grades it — and whether the lab that did this with the network unplugged ever lets the public plug it back in.
On May 25th The Register reported the first ship window for the model Anthropic has spent two months calling too dangerous to release. In its Project Glasswing update, the lab wrote that "in the near future, once we've developed the far stronger safeguards we need, we look forward to making Mythos-class models available through a general release" — and that it will "work with critical partners, including US and allied governments, to expand Project Glasswing to additional partners." This is the pivot the MYTHOS chain has been bending toward since the codename leaked: last week the question was why Anthropic won't ship the cyber model; this week it is when.
The mechanism is the contradiction sitting one sentence away from the promise. The same update that dates a public release also states, flatly, that "at present, no company, including Anthropic, has developed safeguards strong enough to prevent such models from being misused and potentially causing severe harm." The capability is not theoretical. Anthropic disclosed that Mythos Preview constructed a working exploit against wolfSSL — a TLS library it describes as "used by billions of devices worldwide" — that would let an attacker forge certificates and stand up a perfectly legitimate-looking fake bank or email site. That flaw, CVE-2026-5194, is already patched, with a full technical writeup promised in the coming weeks. The pledge, then, is to one day hand the general public a tool that today forges trust on billions of devices, gated only by safeguards that the lab says do not yet exist anywhere.
What lands is the new shape of the velvet rope. The frontier's most dangerous capability is no longer rationed by whether the model exists — it does, and it is already shipping named CVEs into coordinated disclosure — but by trust, in two directions at once. Anthropic widens the inner circle to governments now while deferring the public to a "near future" pinned to a safeguard that has no owner and no date. The bet is that defenders compound the advantage before the general release arrives, the same wager OpenAI is making this week by gating its biodefense model to vetted states. But a release date conditioned on a problem nobody has solved is not a date. It is an IOU written against the one thing the most valuable AI company is now selling, and the collateral is everyone whose certificate the model already learned to forge.
On May 29th, OpenAI launched Rosalind Biodefense and did the one thing the frontier rarely does with a new model: it refused to make it generally available. GPT-Rosalind, a dedicated life-sciences model, opens on two gated tracks and only two — a developer track that hands sponsored access and launch support to vetted biosecurity builders for epidemic modeling, early detection, and screening, and a government track that routes the model to select U.S. and allied public-health and biodefense missions, per the Axios exclusive that broke it. No self-serve tier, no API key, no waitlist that ends in access. The capability is real and the front door is welded shut.
The gate is the architecture, not a footnote on it. OpenAI frames the build around defensive acceleration — the claim that frontier AI should meaningfully advantage defenders over attackers — and operationalizes it as a "trusted access model" with vetted access for defenders, briefing the White House and federal agencies on the approach before shipping. The launch partners are named and concrete: Johns Hopkins Applied Physics Laboratory is wiring GPT-Rosalind into protein-engineering platforms to screen mutant enzymes for therapeutics, and CEPI is pointing it at its 100 Days Mission — compressing vaccine development to 100 days — including the current Ebola outbreak. A model OpenAI had already designated "High Capability" in biology is being deployed by vetting the user, not by trusting the world.
This is the OpenAI mirror of the move Anthropic made the same week. Anthropic pledged to release its Mythos-class cyber models publicly only "once we've developed the far stronger safeguards we need," conceding in the same breath that no company has those safeguards yet — and held the exploit engine back behind a trust gate. OpenAI just built the identical structure in biology: take a dual-use capability too dangerous to broadcast, ration it to screened defenders, and bet the defender gets there first. Two of the three frontier labs now treat their most powerful model as something you qualify for, not something you buy. The default shipped to everyone; the dangerous capability ships to whoever passes the check — and "trusted access" is becoming the deployment pattern for the frontier's sharpest edges.
BMW put humanoid robots on a production line in Germany for the first time — Hexagon's AEON assembling high-voltage batteries at Plant Leipzig, not a demo reel. Last week a humanoid held a warehouse line for 81 hours; this week one joined European serial-production tooling, the threshold that turns the category from capex theater into a line item.
93FIELD REPORTMATTER
A Humanoid Joined BMW's Battery Line. It Is Named AEON, Not Figure.
The category crossed the threshold that matters — off the demo reel, onto a high-voltage assembly line, on home turf.
The robot on the floor at BMW Group Plant Leipzig is not Figure. It is **AEON**, a 1.65-metre humanoid from Zürich-based Hexagon Robotics, and BMW has put it inside high-voltage battery assembly and component manufacturing — the stations where workers today wear heavy protective gear and absorb repetitive strain. It is the first time a humanoid has worked a BMW line in Germany, and the milestone is the geography as much as the machine: BMW already ran one of these pilots in the United States, and is now spreading the bet to a second vendor on home soil.
The threshold this crosses is the only one that has ever mattered for the category — off the demo reel and onto real industrial tooling. This is still a pilot, not full serial production: BMW ran test phases in December 2025 and April 2026 and scales AEON to a permanent pilot in summer 2026, examining where a multifunctional humanoid can slot into the line. What makes it load-bearing is the precedent already banked across the Atlantic. At Plant Spartanburg, Figure's F.02 supported the build of 30,000-plus BMW X3s over roughly ten months of ten-hour shifts before AEON ever reached Leipzig. The category has a production track record now; Germany is BMW deciding it wants two horses in the race.
A humanoid on a battery line is a line item, not a keynote — that is the whole point. Last week a Figure fleet held a warehouse for 81 hours as a livestream stunt; this week one joined European serial-production planning, and the difference between those two facts is the difference between capex theater and a number on a procurement sheet. The same embodiment wave is also arriving in your pocket, not just the plant — Meta is reportedly building an always-listening AI "pendant" for work while Amazon ships its Bee listening wristband, the consumer-grade dystopia you can buy today. But the version that reprices labor wears no badge and clocks in at Leipzig. When the body shows up to the shift, the conversation stops being whether and starts being how many.
Cognition raised $1 billion at a $26 billion valuation on $492 million of run-rate — hard proof the coding-agent application layer is fundable alongside the labs. The same week, GitHub Copilot's switch to token-based billing drew an immediate developer revolt. The capital order flipped and the meter became the UX: the agent got cheaper to build and more expensive to run, and the invoice is now the part users feel.
94FIELD REPORT
Cognition Raised $1 Billion. The App Layer Is Fundable Now.
An independent coding-agent company just got priced at $26 billion alongside the labs that supply its models.
On May 27th, Cognition — the maker of the autonomous software engineer **Devin** and the acquired Windsurf editor — raised more than $1 billion at a $25 billion pre-money, $26 billion post-money valuation. Lux Capital, General Catalyst, and 8VC co-led, with Founders Fund, Ribbit Capital, and Atreides joining existing backer Elad Gil. The round more than doubled the company's worth in the eight months since a September raise valued it at $10.2 billion.
The number underwriting the markup is a $492 million annualized run-rate, growing 50% month-over-month for six straight months, with Mercedes-Benz, NASA, Goldman Sachs, and Santander named as enterprise customers. The detail that makes the valuation legible is who is paying: not developers buying a copilot seat, but enterprises buying the agent as a worker. Cognition now writes more than 90% of its own code with Devin — the product is its own largest reference deployment, which is why a $492 million run-rate clears a 53x multiple without a model lab underneath it.
The capital order flipped this week. The conventional read was that value pools at the model layer and the application layer is a thin wrapper waiting to be absorbed — yet here an independent agent company scales to an eleven-figure valuation in the same window Anthropic passed OpenAI at $965 billion, priced alongside the very Claude Code and Codex it competes with rather than beneath them. The bet the round makes explicit is that the durable margin lives where the work gets done, not where the weights get trained. The labs sell the engine; this week the market decided the company that drives it is worth almost as much.
On May 30th, days before the cutover, GitHub Copilot's switch to token-based billing boiled over into a public developer revolt. Effective June 1st, GitHub retires the flat "premium request" plan and meters Copilot on the tokens a session actually burns — and the devs who run it did the arithmetic and balked. *"What a joke,"* one wrote on Reddit, posting a bill that jumped from roughly $29 a month to nearly $750; the official announcement thread drew more than 400 comments and nearly 900 downvotes, the loudest community backlash GitHub has logged in years.
The mechanism is the whole story. Per GitHub's own announcement, Premium Request Units give way to GitHub AI Credits billed against "input, output, and cached tokens, according to the published API rates for each model" — base subscriptions hold at $10 for Pro and $39 for Pro+, but everything past code completion now draws down a meter at a cent per credit. Two details make it bite: the fallback to a cheaper model when you run dry is gone, and a single agentic session can eat $30 to $40 of credits, so a $10 Pro plan empties in one sitting. The same compute cost that made Microsoft cancel Claude Code internally last week — the token bill it could not absorb — is the cost it just handed to the developers outside the building.
That hand-off is the closing signal of the week. Cognition raised a billion dollars proving the coding agent is a fundable product; GitHub Copilot proved the same week that the product's price is no longer a line on a plan page but a number that moves while you work. The agent got cheaper to build and more expensive to run, and the difference did not vanish — it migrated to the invoice, where the user now reads it in real time. The whole issue tracked a frontier learning to sell trust: trust the honest model, trust the gated capability, trust the clean report. The last thing it asks the reader to trust is the meter, and the meter is the one surface that answers back in dollars.